2022 / Day 01: Points
The idea of this SQL is to check out / portray three different spatial clustering functions that come with PostGIS and see how they work compared to each other. We’ll be looking at:
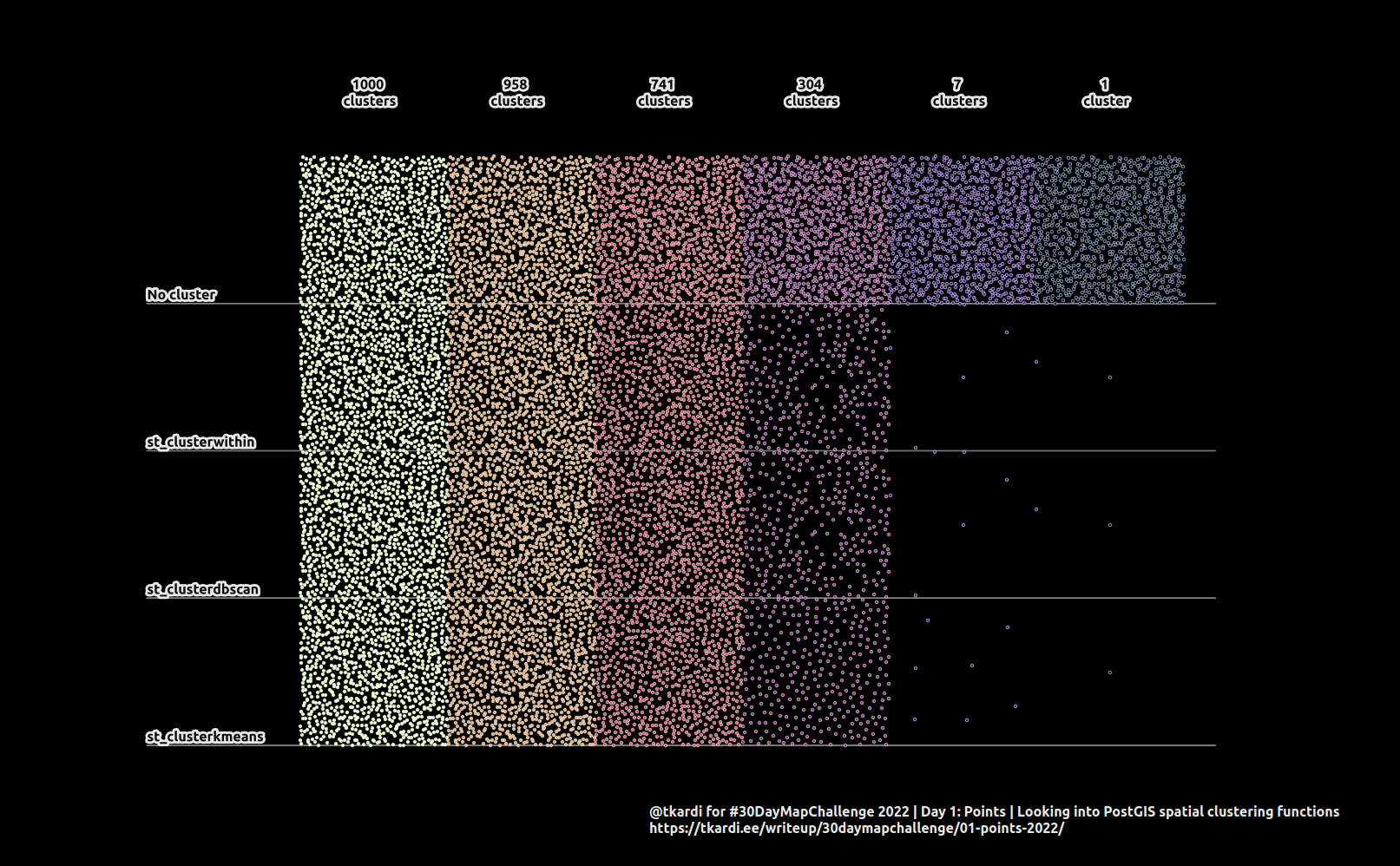
Although they do pretty much the same thing there are still some differences:
st_clusterwithinis an aggregate function, takes a set of geometries and a desired distance parameter, and returns a set of GeometryCollections, one row for each discovered cluster.st_clusterdbscanis a window-function (is this the correct term?), takes a set of geometries, a desired distance parameter, and the minimum number of geometries that should make up a cluster. Returns an integer which identifies the cluster, one for each input row.st_clusterkmeansis similar tost_clusterdbscanonly that it requires the number of desired clusters as input not min distance between them.
In order to make the results comparable the following SQL uses the same set of
random points generated within a specific bounding box, clusters these points
with a fixed set of parameters: 1,10000,20000,30000,40000,50000 m for
st_clusterwithin and
st_clusterdbscan, and
then bases the number of different clusters for
st_clusterkmeans on the
output of st_clusterdbscan.
{kind=link}
One interesting thing to note is that
st_clusterwithin and
st_clusterdbscan both give
very similar results while results for
st_clusterkmeans
look spatially more coherent (especially in the low end of cluster numbers).
with
/* minmax defines the corners where we create a set of random points. */
minmax as (
select
st_point(
40500.000000,5993000.000000,3301
) as ll,
st_point(
1064500.000000,7017000.000000,3301
) as ur
),
/* bounds gives the envelope for them */
bounds as (
select
st_envelope(
st_collect(
array[ll, ur]
)
) as geom
from minmax
),
/* pts will hold the random generated points (1000 pcs) */
pts as (
select
(st_dump(st_generatepoints(bounds.geom, 1000))).geom as geom
from bounds
),
/* clustering the random points using a distance of
1, 10000, 20000, 30000, 40000, 50000 m
using st_clusterwithin */
clw as (
select
i, s,
st_translate(
st_geometricmedian(
st_collectionextract(cl.geom)
),
st_x(minmax.ur) +
s::numeric/10000.0 * (st_x(minmax.ur) - st_x(minmax.ll)),
0
) as geom,
count(1) over(partition by s) as count
from
minmax, (
select
s, st_clusterwithin(pts.geom,coalesce(nullif(s,0),1)) as geom
from
pts, generate_series(0, 50000, 10000) s
group by s
) d
join lateral
unnest(d.geom) with ordinality cl(geom, i) on true
),
/* clustering the random points using a distance of
1, 10000, 20000, 30000, 40000, 50000 m
using st_clusterdbscan */
dbs as (
select
cl, s,
st_translate(
geom,
st_x(minmax.ur) +
s::numeric/10000.0 * (st_x(minmax.ur) - st_x(minmax.ll)),
-1.0*(st_y(minmax.ur) - st_y(minmax.ll))
) as geom,
count(1) over(partition by s) as count
from
minmax, (
select cl, s, st_geometricmedian(st_collect(geom)) as geom
from (
select
s as s,
st_clusterdbscan(
geom,
coalesce(nullif(s,0), 1),
1
) over (partition by s) as cl, geom as geom
from pts, generate_series(0, 50000, 10000) s
) f
group by cl,s
) g
),
/* clustering the random points using numbers of clusters
derived from clusterdbscan clustering from before.
using st_clusterkmeans */
kmeans as (
select
cl, (s-1) * 10000 as s, st_translate(
geom,
st_x(minmax.ur) +
(s::numeric-1.0) * (st_x(minmax.ur) - st_x(minmax.ll)),
-2.0 * (st_y(minmax.ur) - st_y(minmax.ll))
) as geom,
count(1) over(partition by s) as count, f
from
minmax, (
select
cl, s, st_geometricmedian(st_collect(geom)) as geom, f
from (
select
st_clusterkmeans(
pts.geom,
s.elem::int,
1000000
) over(partition by s) as cl, s.i as s, geom, f
from
pts, (
select
array_agg(size order by size desc) as size
from (
select distinct count as size
from dbs
) g
) f
join lateral
unnest(size) with ordinality s(elem, i) on true
) f
group by cl,s, f
) g
)
select
row_number() over ()::int as oid, *
from (
select
'no_cluster' as clustering, s,
st_translate(
geom,
st_x(minmax.ur) + s::numeric/10000.0 *
(st_x(minmax.ur) - st_x(minmax.ll)),
(st_y(minmax.ur) - st_y(minmax.ll))
) as geom,
count(1) over (partition by s) as count,
null::varchar as lbl
from
minmax, generate_series(0, 50000, 10000) s, pts
union all
select
'st_clusterwithin' as clustering, s,
geom,
count,
null::varchar as lbl
from
clw
union all
select
'st_clusterdbscan' as clustering, s,
geom,
count,
null::varchar as lbl
from
dbs
union all
select
'st_clusterkmeans' as clustering, s,
geom,
count,
null::varchar as lbl
from
kmeans
union all
/* and create cluster-count labels on top of columns */
select
null as clustering, s,
st_translate(
minmax.ur,
(s::numeric/10000.0) * (st_x(minmax.ur) - st_x(minmax.ll)) +
(st_x(minmax.ur) - st_x(minmax.ll)) / 2.0 ,
(st_y(minmax.ur) - st_y(minmax.ll)) +
(st_y(minmax.ur) - st_y(minmax.ll)) / 2.0
) as geom,
count,
count::varchar as lbl
from
minmax, (
select 'st_clusterwithin' as clustering, s, count
from clw
group by s, count
union all
select 'st_clusterdbscan' as clustering, s, count
from dbs
group by s, count
union all
select 'st_clusterkmeans' as clustering, s, count
from kmeans
group by s, count
) stat
group by s, count, minmax.ur, minmax.ll
) h
order by clustering, s
;