From points to polygons
Zip code areas. The Estonian zip codes are assigned to addresses based on local administrative division settlements. Usually a zip code is the same for all addresses in a settlement but in some cases like larger cities there are usually many of them. And since zip codes are used to optimize postal flow (rather than addressing) it makes perfect sense. The zip codes are assigned based on street name and house number so it’s absolutely OK for all the house numbers on a street to have the same zip. It might also be that even house numbers have one zip and odd numbers on a street have another zip. Or as a combination of ranges. Or even ranges and odd ranges. Or… you get the picture. So it might end up fairly complicated if we wanted to draw the zipareas as a map layer. The zip code areas could be drawn as a union of voronoi cells around addresspoints but in that case they will not follow street centerlines among other things. And that does work in case you have different zips on either side of the street, and would for example want to assign zipcodes to new addresses based on spatial containment.
It could be argued that zipcodes are not actually geospatial phenomena at all but nevertheless seeing their areal extent on a map and using it in further analysis can help to optimize the way zipcodes are assigned to addresses (essentially a question of optimizing the postal flow).
In the following writeup I will cover the process of creating zip code areas based on streets, rivers, settlement polygons, cadastral parcel data, and addresspoints that already have zip codes assigned. Basically the presented method could be used in different cases when point data needs to be polygonized in a way that takes into account natural or humanmade (linear) phenomena.
I’m mostly writing this down as a way to document it for myself. If you find it useful or interesting or have suggestions then feel free to ping me.
Addendum 19.03.2019
Trying to construct voting district polygons for the whole country from 3,6 million address points... Why this kind of data can't be already openly available? pic.twitter.com/f96e8kuQpv
— Topi Tjukanov (@tjukanov) March 18, 2019
After having initially abandoned writing this post because it seemed too complicated to pin it down as a step-by-step process, I saw this tweet by Topi Tjukanov and was intrigued to still get it finished because there seemed to be some similarity between these tasks of creating areal data out of point-based data.
What follows is to a great part the result of trial and error, best hopes, guesses and countless cups of coffee, back-to-the-drawingboard types of situations. At some points in the following text the SQL queries will be overtly overcomplicated and most probably they can (and should) be written more consistently. But maybe some other time.
Anyway. Don’t expect too much clarity… Don’t expect to take your data and simply run the queries and get the expected result (though, the general idea of the whole flow should still be valid).
But do expect a lot of SQL and images.
Acknowledgments
This work was initially undertaken for AS Eesti Post (Omniva) as an input for the address data update/management system. A shoutout also to UEC OÜ for making it possible for me to work on some (at times) really mind-boggling problems that don’t seem to have an (let alone simple) answer.
Thank you, I learnt how to use looping in PostgreSQL queries :)
The grayscale basemap used in some of the screenshots below is from the Estonian Ministry of the Environment’s WMS service
The other basemap used is by the Estonian Land Board
Input data
The datasets that were used for this work include:
- Settlement level admin units that are “expanded out” to the sea (self-made). See subdividing space for a discussion on how it could be done.
- Streets and railroads data from the Estonian Land Board’s homepage licensed under Licence of open data by Estonian Land Board
- Cadastral parcels from the Estonian Land Board’s homepage licensed under Licence of open data by Estonian Land Board
- River centerlines from the Ministry of Environment’s open access WFS service. Data licensed under CC-BY 4.0: EELIS (Eesti Looduse Infosüsteem - Keskkonnaregister): Keskkonnaagentuur
- Address points with zip codes assigned. This dataset is not currently freely available for download. But it could be combined from the Estonian Land Boards open datasets.
Processing
The basic gist of all this is to create a bunch of polygons that cover the whole area that you’re interested in with no gaps and no ovelaps in between these polygons and then simply classify those using the point data at hand. So if you, dear reader don’t really care for the SQLy-thing then you can stop here because the rest of the story blabbers on and on how to achieve all of this.
Breaking the lines and then assembling again
The first task to do is take all the the linestring data (we’ll gently refer
to this dataset as noise from this point on) and topologically break
them at intersections (just like when preparing road network data for routing).
And then we end up with a lot of lines which we can compose into whatever
polygons however we want to.
So for example noise looks like this
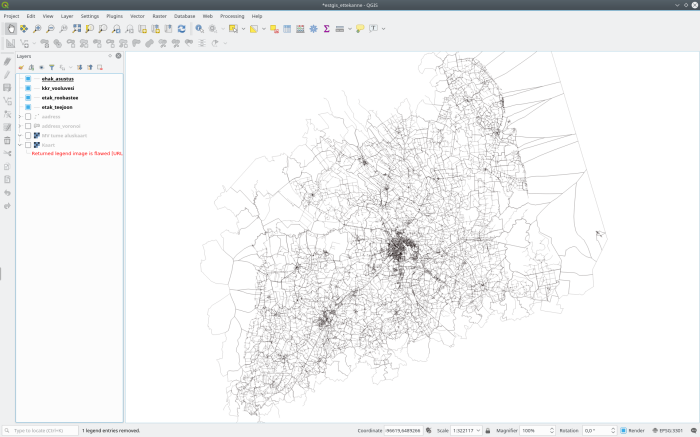
And if we polygonize it, it will be your typical polygons
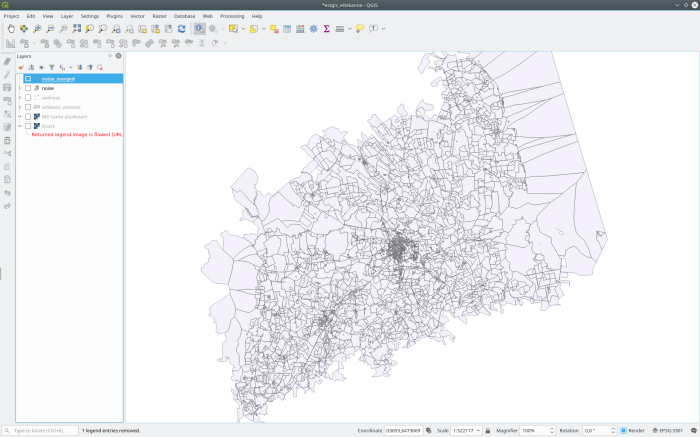
There are different possibilities for doing this but PostGIS is a
really powerful tool for dataprocessing like this. The following SQL uses a
loop to process the data one settlement (identified by akood value) at a time.
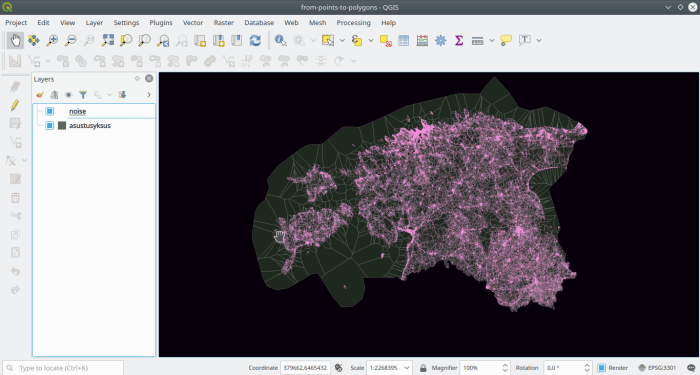
noise is our linestring features table and asustusyksus where the
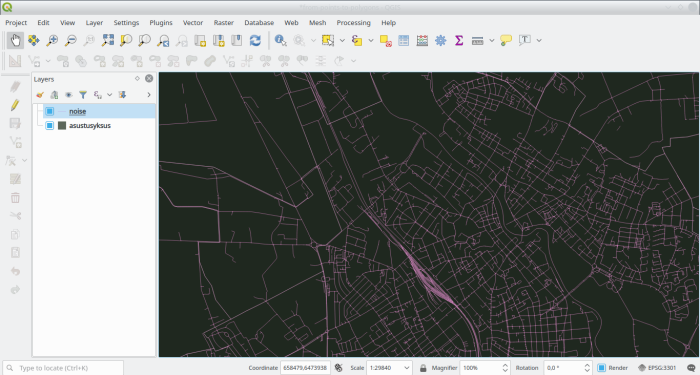
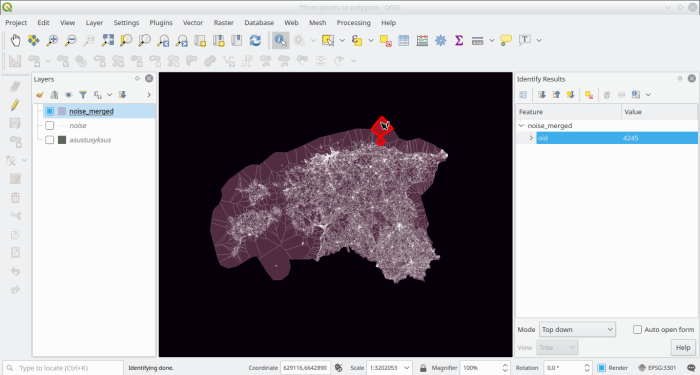
settlements are. The input data looks like this
And for a closeup
So, in a PostGIS database:
-- create the table to hold the result
drop table if exists zip.noise_merged;
create table zip.noise_merged (
oid integer,
geom geometry(Geometry, 3301), -- geometry in Est. Nat. sys
akood varchar(4) -- this is the settlement identifier
);
do
$$
declare
r record;
begin
truncate table zip.noise_merged;
for r in
-- loop by one settlement at the time
select oid, akood, geom
from zip.asustusyksus
order by oid
loop
begin
insert into zip.noise_merged (
oid, akood, geom
)
select
-- let PostGIS do its magic by creating some polygons
-- out of our noise. Dump them to singleparts.
r.oid, bar.akood,
(st_dump(
st_polygonize(
bar.geom
)
)).geom
from (
-- node the noise and settlement units, and
-- dump them to singleparts
-- don't forget a reasonable snaptogrid here.
select
(st_dump(
st_node(
st_collect(
st_snaptogrid(
foo.geom,
0.005
)
)
)
)).geom as geom, akood
from (
-- get the intersection of noise in this settlement
select
r.akood, (st_dump(
st_intersection(n.geom, r.geom)
)).geom
from zip.noise n
where st_intersects(n.geom, r.geom)
union all
-- and add settlement area geometries' all rings
-- dumped to linestrings
select
r.akood, st_exteriorring(
(st_dumprings(r.geom)).geom
) as geom
) foo
where geometrytype(foo.geom) = 'LINESTRING'
group by akood
) bar
group by akood;
if r.oid % 100 = 1 then
-- raise a message to show how far we've come after every 100
-- settlements that have been processed
raise notice '%, %', clock_timestamp(), r.oid;
end if;
exception
when others then
raise warning 'Loading of record % failed: %', r.akood, SQLERRM;
end;
end loop;
end
$$;
alter table zip.noise_merged add column gid serial;
alter table zip.noise_merged add constraint pk__noisemerged primary key (gid);
create index sidx__noise_merged on zip.noise_merged using gist(geom);Which might take some time but will eventually output a result like in the following images
and closeup
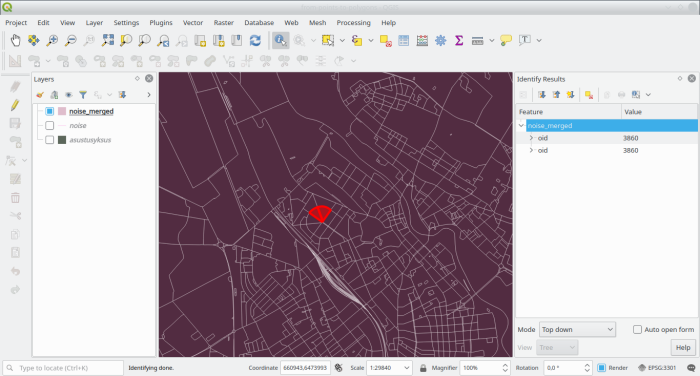
These form the basis for the classification we’ll uptake next, and therefore
to keep some context with the data, lets refer to them as quartiers. It would be
advisable to topo-check this layer aswell with something like GRASS'
v.clean for example.
Still. The good thing now is that any point data you have and need to
turn into polygons can be done based on this same set of quartiers.
Classifying the quartiers
Now with zipcodes the first thing we’ll check is whether all address points
in a settlement (that is, a unit identified by akood) have the same zip. With
this we’ll have a pretty good amount of quartiers already settled.
-- create table listing all possible combinations
-- of adminunits-to-zipcodes
drop table if exists zip.distinct_zip;
create table zip.distinct_zip as
select
distinct mkood as a1, okood as a2, akood as a3,
postiindeks as zip
from zip.addrespoint;
-- keeping track which quartier has a zip assigned
alter table noise_merged add column gotzip boolean;
-- and make a new table based on those settlements
-- that only have one zip code
drop table if exists zip.zip_areas;
create table zip.zip_areas as
select
d.a1, d.a2, d.a3, d.zips[1] as zip, nmt.gid as nm_gid,
nmt.geom
from (
select
a1, a2, a3, array_agg(zip) as zips,
count(1) as zip_count
from zip.distinct_zip
group by a1, a2, a3
having count(1) = 1
order by a1, a2, a3
) d, zip.noise_merged nmt
where nmt.akood = d.a3;
-- mark these quartiers as used
update zip.noise_merged set
gotzip = true
from zip.zip_areas
where zip_areas.nm_gid = noise_merged.gid;Next up get all overleft quartiers which have only one zipcode available (
through e.g. st_within spatial relation). Precalculate distincts
drop table if exists zip.distinct_zip_noise;
create table zip.distinct_zip_noise as
select gid, a3, array_agg(zip) as zips, count(1) as zip_count
from (
select nmt.gid, nmt.akood as a3, pa.postiindeks as zip
from zip.noise_merged nmt, zip.addresspoint pa
where st_within(pa.geom, nmt.geom)
and nmt.gotzip is null
group by nmt.gid, nmt.akood, pa.postiindeks
) foo
group by gid, a3;And now add some more quartiers as zip areas
insert into zip.zip_areas (
a1, a2, a3,
zip, nm_gid, geom
)
select
ay.mkood as a1, ay.okood as a2, ay.akood as a3,
d.zips[1] as zip, nmt.gid as nm_gid, nmt.geom
from (
select
n.gid, n.a3, n.zips
from zip.distinct_zip_noise n
where zip_count = 1
) d, zip.noise_merged nmt, (
select
distinct akood, okood, mkood
from zip.asustusyksus) ay
where nmt.gid = d.gid and d.a3 = ay.akood and nmt.gotzip is null;
update zip.noise_merged set
gotzip = true
from zip.zip_areas
where
zip_areas.nm_gid = noise_merged.gid and
noise_merged.gotzip is null;Now looking at the layer we can see, that there are still quite many unclassified quartiers - part of them is missing an addresspoint within them, and the other part has more than one zip.
With the first part (no addrespoint) we cannot do anything much right now. But
if there are more than one distinct zip codes present with addresspoints in the
quartier, then we could either divide the quartier through voronoi polygons,
or use some inner-quartier features, e.g. cadastral parcels.
Dividing some more with cadastral parcels
Luckily, the Estonian Land Board has made the cadastral parcel data open with a permissive licence so you can freely download it and use it. (Note: this dataset needs to be topologically corrected before, removing overlaps, self-intersections and the like). But, as before, we’ll start by selecting only those parcels that have address points with one distinct zip only.
drop table if exists zip.parcel_noise;
create table zip.parcel_noise as
select
*
from (
select
k.gid, nmt.gid as nm_gid, k.geom as geom
from zip.parcel k, zip.noise_merged nmt
where
st_intersects(k.geom, nmt.geom) and
st_touches(k.geom, nmt.geom) = false and
nmt.gotzip is null
) foo
where geometrytype(geom) = 'POLYGON';
alter table zip.parcel_noise add column oid serial;
alter table zip.parcel_noise add constraint pk__kataster_noise primary key (oid);
create index sidx__parcel_noise on zip.parcel_noise using gist (geom);which outputs a layer like
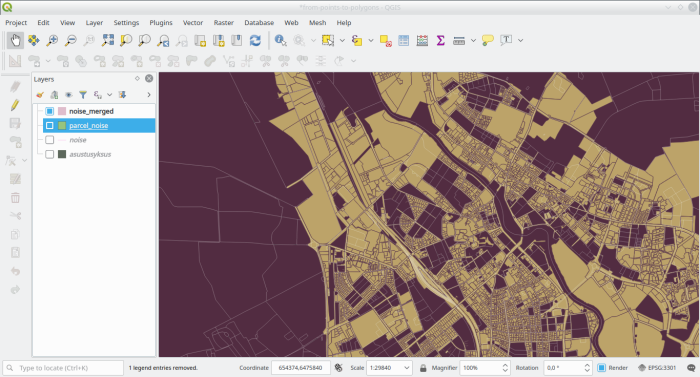
Let’s record the distinct zipcodes available in these “parcels split by
quartiers”
alter table zip.parcel_noise add column zips varchar[];
update zip.parcel_noise set
zips = n.zips
from (
select
kn.oid, array_agg(distinct pa.postiindeks) as zips
from zip.parcel_noise kn, zip.addresspoint pa
where st_within(pa.geom, kn.geom)
group by kn.oid
) n
where n.oid = parcel_noise.oid;Now taking out first those that have only one distinct zip present
drop table if exists zip.parcel_noise_pazip;
create table zip.parcel_noise_pazip as
select
array_agg(kn.oid) as kn_oid, kn.nm_gid, kn.pa_zips[1] as zips,
st_union(kn.geom) as geom
from zip.parcel_noise kn
where array_length(kn.pa_zips, 1) = 1
group by kn.nm_gid, kn.zips;Those parcels that have more than one distinct zip present could be then further divided based on something. For this layer’s creation we decided to keep a comma-separated list of zips for these parcels to be further refined later on case-by-case by a specialist.
drop table if exists zip.parcel_noise_zip;
create table zip.parcel_noise_zip as
select
n.*
from (
select
bar.knoid, bar.nm_gid, zip, (st_dump(
st_intersection(bar.geom, nmt.geom)
)).geom as geom
from (
select
array_agg(knoid) as knoid, nm_gid, zip,
st_union(geom) as geom
from (
select
n.knoid, kn.nm_gid, kn.geom as geom,
array_to_string(kn.zips,',') as zip
from (
select
unnest(array_agg) as knoid
from zip.parcel_noise_pazip
union
select
oid
from zip.parcel_noise
where array_length(zips, 1) > 1
) n, zip.parcel_noise kn
where kn.oid = n.knoid
) foo
group by nm_gid, zip
) bar, zip.noise_merged nmt
where bar.nm_gid = nmt.gid
) n
where geometrytype(geom) = 'POLYGON';
alter table zip.parcel_noise_zip add column oid serial;
alter table zip.parcel_noise_zip add constraint pk__parcel_noise_zip primary key (oid);Remove all parcels from this game that don’t have an addresspoint
alter table zip.parcel_noise_zip add column has_ap boolean;
update zip.parcel_noise_zip set
has_ap = true
from zip.addrespoint
where st_within(addresspoint.geom, parcel_noise_zip.geom);
delete from zip.parcel_noise_zip where has_ap is null;And then marvel at the output.
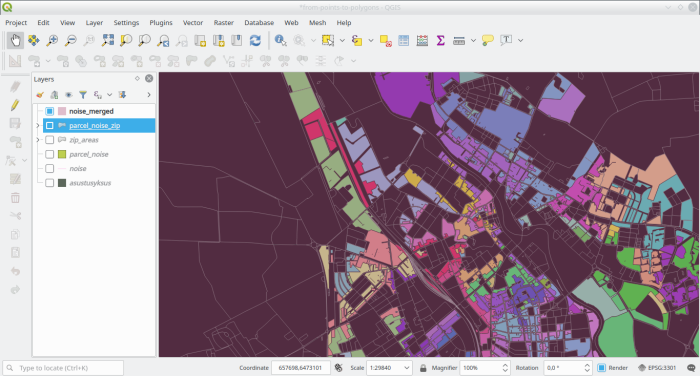
And if we add the already classified areas to the map aswell:
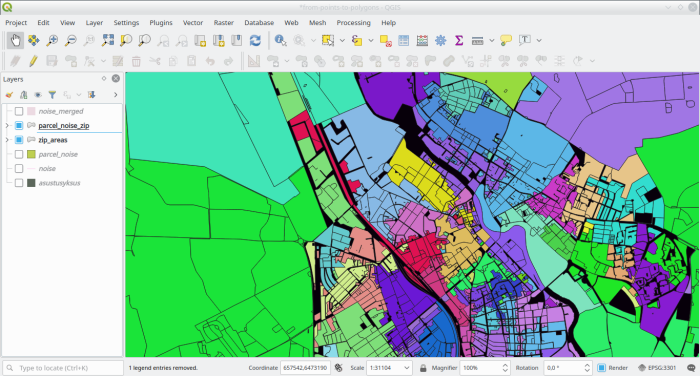
So there are still gaps in between the classified areas. One way to overcome
this is by dividing the space within a quartier between the parcels that are
there already. The steps of the process are the same as described in
a previous post so I won’t go into any details
with this here. To walk through the main points of the process still:
- select the parcels that need to be expanded/stretched to fill the empty space (i.e. those that are already classified),
- calculate single-part shared edges within
quartiersfor these parcels, - out of all those shared edges, take only those that border 1 parcel (NB!
within a
quartier), - extract the vertices and build voronois (for a better result add
addresspoints into the voronoi input point lot aswell) on a
quartier-basis, cookie-cutthequartier-based voronois first withquartiersthemselves (i.e. remove those parts of voronois that go outside of thequartierthat they belong to),- find the difference with all other already classified areas (i.e. subtract from the created voronois the space that’s alredy taken up by areas that are already classified and don’t represent the same thing, value, class or however we call it…)
- and finally union the postprocessed voronois with the original areas within
the
quartier(later referenced aszip.parcel_noise_zip_trimmedtable).
When done with this we have a nice layer of cadastral parcels expanded
within the limits of quartiers.
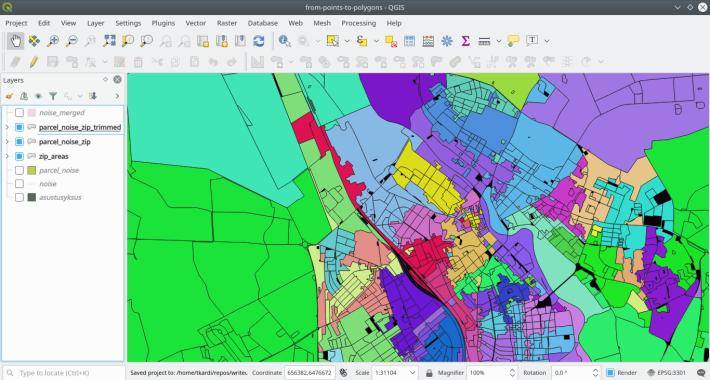
And as John Mcclane would say at this point: “HO-HO-HO! Now I have a classified
map of all quartiers that have at least one addresspoint within.” In order to
merge it all together some postprocessing is needed though (snapping, noding
and removing other oddities).
Will this ever be over and done with?
Unfortunately here is the point where it gets a bit messy and it’s quite a bit of a trial and error approach from here on. Doing something, checking it and then going with your gut feeling.
Anyway. First (after getting your next cup of coffee/tea/mineralwater/etc. whichever you prefer) do a preflight snaptogrid and store the polygons in the same table
drop table if exists zip.zip_alls_pre;
create table zip.zip_alls_pre as
select
-- mix everything together, dump all rings
row_number() over ()::int as _mid_, a3, nm_gid, zip,
(st_dumprings(geom)).*
from (
-- one pinch of settlements with only one distinct zip
select
a3, nm_gid as nm_gid, zip,
(st_dump(st_snaptogrid(geom, 0.001 ))).geom as geom
from zip.zip_areas
union all
-- one pinch of parcels with distinct zips
select
nmt.akood as a3, knz.nm_gid as nm_gid, knz.zip,
(st_dump(st_snaptogrid(knz.geom, 0.001))).geom as geom
from zip.parcel_noise_zip knz, zip.noise_merged nmt
where knz.nm_gid = nmt.gid
union all
-- and one pinch of parcels with the socalled `expanded areas`
select
a3, nm_gid as nm_gid, zip,
(st_dump(st_snaptogrid((st_dump(geom )).geom, 0.001))).geom as geom
from (
select a3, nm_gid, zip, st_union(geom) as geom
from zip.parcel_noise_zip_trimmed
group by a3, nm_gid, zip
) n
) foo;Node the polygon boundaries as needed by extracting all rings, noding them and then reconstructing the polygons. The output of this is the discs that will make up the later polygons with separate rows for shells and holes not the areas themselves)
drop table if exists zip.zip_alls;
create table zip.zip_alls as
select
a3, zip, array_agg(distinct nm_gid) as nm_gid,
(st_dump(st_union(geom))).geom as geom
from (
select
a3, pre.nm_gid, zip,
(st_dump(st_union(geom))).geom as geom
from (
select
a3, zip, _mid_,
(st_dump(st_buildarea(st_collect(ring)))).geom as geom
from (
select
_mid_, a3, zip,
st_node(st_collect(
case when path[1] = 0 then st_exteriorring(geom)
else st_reverse(st_exteriorring(geom)) end
)) as ring
from zip.zip_alls_pre zab
group by a3, zip, _mid_
) n
group by a3, zip, _mid_
) m, (
select
_mid_, nm_gid as nm_gid
from zip.zip_alls_pre
) pre
where m._mid_ = pre._mid_
group by a3, nm_gid, zip
) zoo
group by a3, zip;
create index sidx__zip_alls on zip.zip_alls using gist(geom);
alter table zip.zip_alls add column oid serial;
alter table zip.zip_alls add column fixed geometry(Geometry, 3301);Now for reconstructing the fixed geometries, coincidentally removing holes from polygons but only if the holes have no other ziparea intersecting them and they dont have any addresspoint within them.
do
$$
declare
rec record;
begin
for rec in
select oid, geom, zip
from zip.zip_alls
order by oid
loop
begin
with
rings as (
select
path[1] as path, geom as ring
from (
select (st_dumprings(rec.geom)).*
) a
), shell as (
select
ring as geom
from rings
where path = 0
), holes as (
select st_reverse(rings.ring) as geom
from rings, (
select distinct path
from rings r, zip.addresspoint pa
where
st_contains(r.ring, pa.geom) and
r.path > 0 and
pa.r_id is not null and
pa.postiindeks != rec.zip
) p
where p.path = rings.path
)
update zip.zip_alls set fixed = n.geom
from (
select st_buildarea(st_collect(geom)) as geom
from (
select geom from shell
union all
select geom from holes) a
) n
where zip_alls.oid = rec.oid;
if rec.oid % 1000 = 1 then
-- after every 1K raise a notice so we just
-- know the thing is running
raise notice '%, %', clock_timestamp(), rec.oid;
end if;
exception
when others then
raise warning 'Loading of record % failed: %', rec.oid, sqlerrm;
end;
end loop;
end;
$$
create index sidx__zip_alls__fixed on zip.zip_alls using gist(fixed);Get rid of those pesky GEOMETRYCOLLECTIONs. Should have dumped them already
in the previous query but of course not…
update zip.zip_alls set
fixed = n.geom
from (
select oid, st_union(geom) as geom
from (
select oid, (st_dump(fixed )).geom
from zip.zip_alls
where geometrytype(fixed) = 'GEOMETRYCOLLECTION'
) k
where geometrytype(geom) = 'POLYGON'
group by oid
) n
where n.oid = zip_alls.oid;But these last things in turn introduced some overlaps we definitely don’t want, so will need to hack the way out somehow
drop table if exists zip.parcel_noise_distincts;
create table zip.parcel_noise_distincts as
select
nm_gid, array_agg(zip) as zips, a3,
count(1) as zipcount
from (
select distinct nm_gid, zip, a3
from (
select unnest(nm_gid) as nm_gid, zip, a3
from zip.zip_alls
) foo
) bar
group by nm_gid, a3;
-- try to fix the already fixed geometries
update zip.zip_alls set
fixed = st_union(zip_alls.fixed, n.geom)
from (
select
oid, zip, st_union(geom) as geom
from (
select zip_alls.oid, zip_alls.zip, g.a3,
st_buffer(
st_snaptogrid(
(st_dump(st_union(zip_alls.fixed, g.geom))).geom,
0.0001
),
0
) as geom
from zip.zip_alls, (
select
d.nm_gid, d.zips[1] as zip,
nmt.geom, nmt.akood as a3
from
zip.parcel_noise_distincts d,
zip.noise_merged nmt
where
d.zipcount = 1 and
d.nm_gid = nmt.gid and
d.a3=nmt.akood
) g
where
st_intersects(zip_alls.fixed, g.geom) and
g.nm_gid = any(zip_alls.nm_gid) and
zip_alls.zip = g.zip and
zip_alls.a3 = g.a3
) k
where geometrytype(geom) = 'POLYGON'
group by oid, zip
) n
where n.oid = zip_alls.oid;
-- and mark the `quartiers` as occupied, but not quite...
-- just in case a "rollback" is required with a `false`
-- flag (facepalm)
update zip.noise_merged set
gotzip = false
from (
select distinct unnest(nm_gid) as nm_gid
from zip.zip_alls
) n
where
n.nm_gid = noise_merged.gid and
gotzip is null;
-- something-something abt the holes we removed before
update zip.noise_merged set
gotzip = false
from (
select nmt.gid
from zip.noise_merged nmt, zip.zip_alls_2 z
where st_within(nmt.geom, z.fixed)
and nmt.gotzip is null
) n
where
n.gid = noise_merged.gid and
noise_merged.gotzip is null;And hopefully we’re now in the clear. There are some overlaps between areas
still left, but these are adjacent quartiers with the same zip value so just
not to make this situation any more difficult let them be for the moment
because in the end we’ll be aggregating all areas based on zip codes anyway.
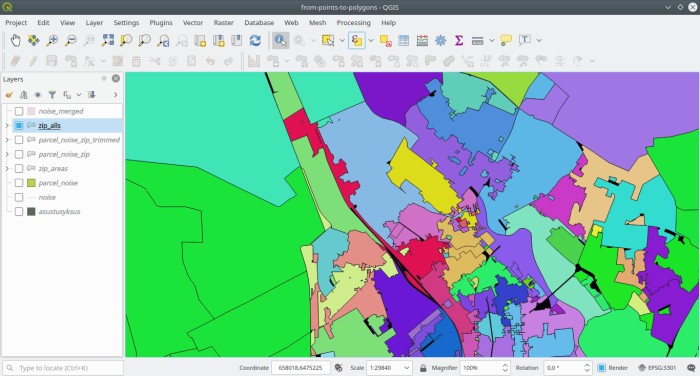
Filling holes
There are still some unclassified quartiers left in the dataset though. One
way to fill these is to classify them by the longest shared edge that they have
with a neighboring already classified quartier.
But first a quick helper function for calculating a shared border between two polygons.
create or replace function shared_border(geometrya geometry, geometryb geometry)
returns geometry as
$$
declare
outgeom geometry;
rings geometry;
begin
execute '
with
geoms as (
select (st_dump(geom)).geom
from (
select st_makevalid(unnest(array[$1, $2])) as geom
) n
), linears as (
select row_number() over()::int as rid, foo.*
from (
select st_linemerge(geom) as geom
from (
select
(st_dump(
st_node(st_collect(geom))
)).geom as geom
from (
select st_exteriorring(
(st_dumprings(geoms.geom)).geom
) as geom
from geoms
where geometrytype(geoms.geom) = $3
) bar
) zab
) foo
), pnts as (
select rid, st_lineinterpolatepoint(geom, 0.5) as geom
from linears
)
select st_collect(geom) as geom
from (
select st_linemerge(st_collect(geom)) as geom
from (
select (st_dump(st_union(linears.geom))).geom as geom
from geoms, pnts, linears
where
st_intersects(st_buffer(pnts.geom, 1), geoms.geom) and
linears.rid = pnts.rid
group by pnts.rid
having count(1)>1
) n
) m'
into outgeom
using geometrya, geometryb, 'POLYGON';
return outgeom;
end;
$$
language plpgsql;This is best done in two loops. One to loop the array of quartiers within the
settlement unit by settlement unit at a time and one to loop the quartiers
from the aggregated array until either all are classified or
no classification is possible (because of no shared edges). We’ll order the
quartiers array based on their area in ascending order (because we
want the reference dataset to grow slowly).
do
$$
declare
main record;
arr integer[];
prev_arr integer[];
el integer;
d record;
i integer := 1;
counter integer := 0;
begin
for main in
-- main loop for looping settlements
select array_agg(gid) as arr, akood, count(1)
from (
select nmt.gid, nmt.akood
from zip.noise_merged nmt
where nmt.gotzip is null
order by akood, st_area(geom) asc
) foo
group by akood
loop
counter := counter + 1;
arr := main.arr;
i := 1;
raise notice 'counter: %, A3: %, COUNT: %, QUARTIERS: %',
counter, main.akood, main.count,
array_to_string(arr, ',');
while array_length(arr,1) > 0
-- inner loop for looping `quartiers` ad nauseam
loop
el := arr[i];
begin
with alls as (
select
n.zip, qgeom,
st_length(
shared_border(n.geom, n.qgeom)
) as len
from (
select
n.zip, st_union(n.fixed) as geom,
min(r.geom)::geometry as qgeom
from zip.zip_alls n, (
select geom, akood
from zip.noise_merged
where gid = el
) r
where
st_intersects(n.fixed, r.geom) and
n.a3 = r.akood
group by n.zip
) n
order by 2 desc
), maxs as (
select max(len) as maxlen
from alls
)
insert into zip.zip_alls (
a3, nm_gid, zip, fixed
)
select
main.akood, array[el],
alls.zip, alls.qgeom
from alls, maxs
where alls.len = maxs.maxlen
order by alls.len desc, alls.zip desc
limit 1
returning zip_alls.* into d;
if (
d.a3 is not null or
(array_length(arr,1)=1 and d.a3 is null)
) then
-- means this `quartier` got an assignment
-- or it was the last one left in the array.
-- Remove this `quartier` from the array.
-- and set the loop to start on the
-- first element again
execute '
select array_remove($1, $2)'
into arr using arr, el;
i := 1;
else
-- means we didn't find anything next to
-- this quartier, tough luck.
if i < array_length(arr,1) then
-- Just take the next one.
i := i + 1;
else
-- well, exit loop because we're
-- at the last `quartier` of the list
-- and there's no point in starting
-- all over again cos nothing
-- has changed from the last run
prev_arr := arr;
exit;
end if;
end if;
end;
if prev_arr = arr then
raise warning
'PROBLEMS with oid: %, arr: %, i:%, el:%',
d.oid, array_to_string(arr, ','), i, el;
exit;
end if;
end loop;
end loop;
end$$This classifies the addresspoint-less layer like
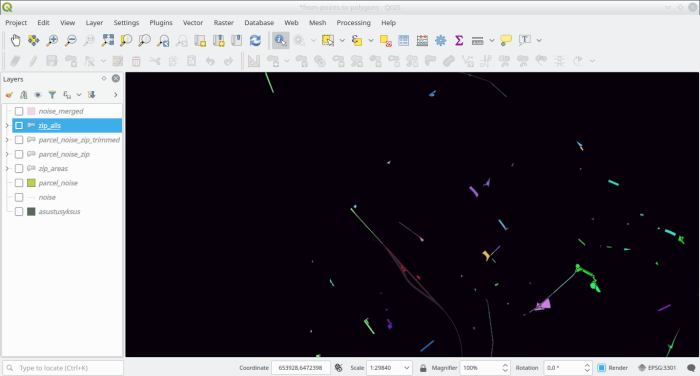
And putting them all together yields
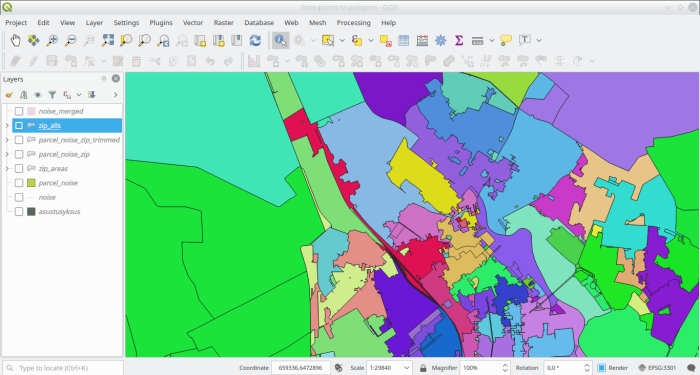
Post-process and some finishing touches
For optimizing the layer (say what?), we’ll do a bit of recalculation for those zip areas that don’t have any addresspoints in them and reassign them zipcodes based on the longest shared edge (like before with filling the gaps).
First off merge all geometries based on zip and settlement code and dump to single-parts.
drop table if exists zip.zip_alls_merged;
create table zip.zip_alls_merged as
select
*
from (
select
zip, a3, (st_dump(geom)).geom
from (
select zip, st_union(fixed) as geom, a3
from zip.zip_alls
group by zip, a3
) foo
) bar
where geometrytype(geom) = 'POLYGON';
alter table zip.zip_alls_merged
add column oid serial;
alter table zip.zip_alls_merged
add constraint pk__zip_alls_merged primary key (oid);
create index sidx__zip_alls_merged
on zip.zip_alls_merged using gist(geom);Now count the number of addresspoints in the areas
alter table zip.zip_alls_merged add column address_count integer;
update zip.zip_alls_merged set
address_count = n.count
from (
select zam.oid, count(1)
from zip.addresspoint ap, zip.zip_alls_merged zam
where st_within(ap.geom, zam.geom)
and ap.postiindeks is not null
group by zam.oid
) n
where n.oid = zip_alls_merged.oid;And then reassign zips for addresspoint-less areas with a zip based on the longest shared edge.
alter table zip.zip_alls_merged add column new_zip varchar;
with
alls as (
select oid, zip, st_length(shared_border(z, o)) as len
from (
select
zam.oid, o.zip, min(zam.geom)::geometry as z,
st_union(o.geom) as o
from
zip.zip_alls_merged zam,
zip.zip_alls_merged o
where
zam.address_count is null and
o.address_count > 0 and
st_intersects(zam.geom, o.geom) and
zam.a3 = o.a3
group by zam.oid, o.zip
) foo
),
maxs as (
select oid, max(len) as maxlen
from alls
group by oid
)
update zip.zip_alls_merged set
new_zip = alls.zip
from alls, maxs
where
alls.len = maxs.maxlen and
alls.oid = maxs.oid and
alls.oid = zip_alls_merged.oid;And finally we’re totally done and we’ll aggregate the areas once again. This time finally. Or… maybe… yes… hope so… but you never know until done and maybe not…
drop table if exists zip.zip_alls_merged_2;
create table zip.zip_alls_merged_2 as
select
zip, a3, (st_dump(geom)).geom
from (
select
coalesce(new_zip, zip) as zip, a3,
st_union(geom) as geom
from zip.zip_alls_merged
group by 1,2
) n;
create index sidx__zip_alls_merged_2
on zip.zip_alls_merged_2 using gist(geom);
alter table zip.zip_alls_merged_2
add column oid serial;
alter table zip.zip_alls_merged_2
add constraint pk__zip_alls_merged_2 primary key (oid);Which in fact does leave us with a nice zipcode areas layer which has its
borders run along street and river centerlines, settlement boundaries and any
other data that was initially used for creating the building-blocks or
quartiers)
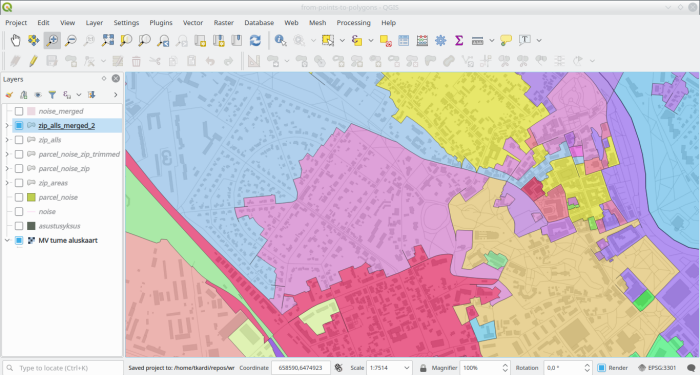
Zooming out a bit
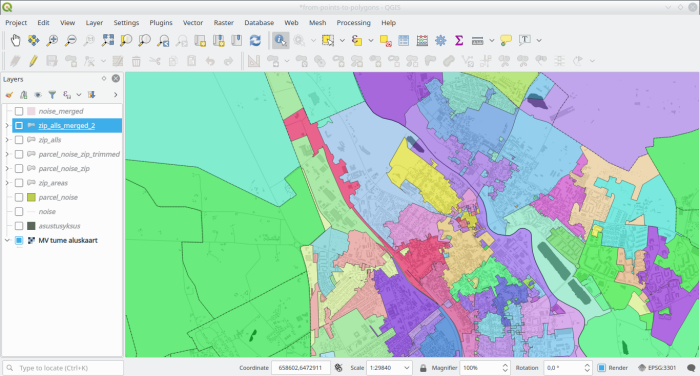
And viewing the whole country
And to wrap it up, the layer should be topologically cleaned again, just as
with the production of noise.